
Potresti già avere familiarità con le medie di carico di Linux. Le medie di carico sono i tre numeri mostrati con i comandiuptime etop – hanno questo aspetto:
La maggior parte delle persone ha un’idea di cosa significano le medie di carico: i tre numeri rappresentano le medie per periodi di tempo progressivamente più lunghi (medie di uno, cinque e quindici minuti) e che i numeri più bassi sono migliori. Numeri più alti rappresentano un problema o una macchina sovraccaricata. Ma qual è la soglia? Cosa costituisce valori medi di carico” buoni “e” cattivi”? Quando dovresti essere preoccupato per un valore medio di carico e quando dovresti arrampicarti per risolverlo al più presto?
Innanzitutto, un po ‘ di background su cosa significano i valori medi di carico., Inizieremo con il caso più semplice: una macchina con un processore single-core.
L’analogia del traffico
Una CPU single-core è come una singola corsia di traffico. Immaginate di essere un operatore di ponte … a volte il ponte è così occupato ci sono auto in fila per attraversare. Vuoi far sapere alla gente come si muove il traffico sul tuo ponte. Una metrica decente sarebbe il numero di auto in attesa in un determinato momento. Se non ci sono auto in attesa, i conducenti in arrivo sanno che possono attraversare subito. Se le auto vengono sottoposte a backup, i conducenti sanno che sono in ritardo.,
Quindi, Operatore Bridge, quale sistema di numerazione userai? Che ne dici di:
- 0.00 significa che non c’è traffico sul ponte. Infatti, tra 0.00 e 1.00 significa che non c’è nessun backup, e una macchina in arrivo sarà solo andare a destra su.
- 1.00 significa che il ponte è esattamente alla capacità. Tutto è ancora buono, ma se il traffico diventa un po ‘ più pesante, le cose stanno andando a rallentare.
- oltre 1.00 significa che c’è il backup. Quanto? Beh, 2.00 significa che ci sono due corsie vale la pena di auto totale total una corsia vale la pena sul ponte, e una corsia vale la pena aspettare. 3.,00 significa che ci sono tre corsie per un valore totale — una corsia vale la pena sul ponte, e due corsie vale la pena aspettare. Ecc.
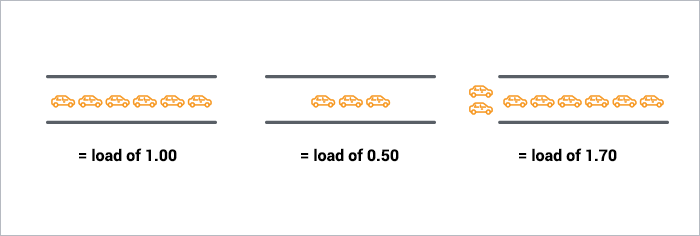
Questo è fondamentalmente ciò che è il carico della CPU. “Auto” sono processi che utilizzano una fetta di tempo della CPU (“attraversando il ponte”) o in coda per utilizzare la CPU. Unix si riferisce a questo come la lunghezza della coda di esecuzione: la somma del numero di processi attualmente in esecuzione più il numero che è in attesa (in coda) per l’esecuzione.
Come l’operatore del ponte, vorresti che le tue auto / processi non aspettassero mai. Quindi, il carico della CPU dovrebbe idealmente rimanere al di sotto di 1.00., Inoltre, come l’operatore del ponte, sei ancora ok se ottieni alcuni picchi temporanei sopra 1.00 … ma quando sei costantemente sopra 1.00, devi preoccuparti.
Quindi stai dicendo che il carico ideale è 1.00?
Beh, non esattamente. Il problema con un carico di 1.00 è che non hai spazio libero. In pratica, molti amministratori di sistema tracceranno una linea a 0.70:
-
La regola empirica “Need to Look into it”: 0.70 Se la media del carico è superiore a> 0.70, è tempo di indagare prima che le cose peggiorino.
-
La regola empirica “Correggi ora”: 1.00., Se la media del carico rimane superiore a 1,00, trova il problema e risolvilo ora. Altrimenti, ti sveglierai nel cuore della notte, e non sarà divertente.
-
Il ” Arrgh, sono le 3 del mattino WTF?”Regola empirica: 5.0. Se la tua media di carico è superiore a 5.00, potresti essere in guai seri, la tua scatola è appesa o rallentata, e questo (inspiegabilmente) accadrà nel peggior momento possibile come nel cuore della notte o quando stai presentando a una conferenza. Non lasciare che ci arrivi.
Che dire di Multi-processori? Il mio carico dice 3.,00, ma le cose vanno bene!
Hai un sistema quad-processor? È ancora sano con un carico di 3.00.
Stesso con le CPU: un carico di 1.00 è l’utilizzo della CPU al 100% su una scatola single-core. Su una scatola dual-core, un carico di 2.00 è il 100% di utilizzo della CPU.
Multicore vs. multiprocessore
Mentre siamo sull’argomento, parliamo di multicore vs. multiprocessore. Ai fini delle prestazioni, una macchina con un singolo processore dual-core è fondamentalmente equivalente a una macchina con due processori con un core ciascuno? Sì. Circa., Ci sono molte sottigliezze qui riguardanti la quantità di cache, la frequenza delle consegne di processo tra processori, ecc. Nonostante questi punti più fini, ai fini del dimensionamento del valore di carico della CPU, il numero totale di core è ciò che conta, indipendentemente dal numero di processori fisici distribuiti su tali core.
Che ci porta a due nuove regole empiriche:
-
La regola empirica “numero di core = carico massimo”: su un sistema multicore, il carico non deve superare il numero di core disponibili.,
-
La regola empirica “core is core”: come i core sono distribuiti sulle CPU non importa. Due quad-core = = quattro dual-core = = otto single-core. Sono tutti e otto i core per questi scopi.
Portandolo a casa
Diamo un’occhiata alle medie di carico di uscita dauptime:
23:05 su 14 giorni, 6:08, 7 utenti, medie di carico: 0.65 0.42 0.36
Questo è su una CPU dual-core, così abbiamo un sacco di headroom. Non ci penserò nemmeno fino a quando il carico non arriva e rimane sopra 1.7 o giù di lì.
Ora, che dire di quei tre numeri? 0.,65 è la media dell’ultimo minuto, 0,42 è la media degli ultimi cinque minuti e 0,36 è la media degli ultimi 15 minuti. Il che ci porta alla domanda:
Quale media dovrei osservare? Uno, cinque o 15 minuti?
Per i numeri di cui abbiamo parlato (1.00 = risolvilo ora, ecc.), dovresti guardare le medie di cinque o 15 minuti. Francamente, se la tua casella supera 1.0 sulla media di un minuto, stai ancora bene. È quando la media di 15 minuti va a nord di 1.0 e rimane lì che devi scattare., (ovviamente, come abbiamo imparato, regola questi numeri al numero di core del processore che il tuo sistema ha).
Quindi # di core è importante per interpretare le medie di carico … come faccio a sapere quanti core ha il mio sistema?
cat /proc/cpuinfo per ottenere informazioni su ciascun processore nel sistema. Nota: non disponibile su OSX, Google per alternative. Per ottenere solo un conteggio, eseguirlo attraverso grep e conteggio delle parole:grep 'model name' /proc/cpuinfo | wc -l
Altri server? O codice più veloce?
L’aggiunta di server può essere un cerotto per il codice lento., Scout APM ti aiuta a trovare e correggere il tuo codice inefficiente e costoso. Identifichiamo automaticamente le chiamate SQL N + 1, il gonfiore della memoria e altri problemi relativi al codice in modo da poter dedicare meno tempo al debug e più tempo alla programmazione.
Pronto per ottimizzare il tuo sito? Iscriviti per una prova gratuita.
Più lettura
- Wikipedia – Una buona, breve spiegazione della media del carico; va un po ‘ più in profondità nella matematica
- Linux Journal – articolo molto ben scritto, va più in profondità di questo post o della voce di wikipedia.,
Maggiori informazioni sulle prestazioni di Linux
- Comprensione dell’I / O del disco-quando dovresti essere preoccupato?
- Determinazione della memoria libera su Linux
Iscriviti al nostro feed RSS o seguici su Twitter per maggiori informazioni sulle prestazioni di Linux.